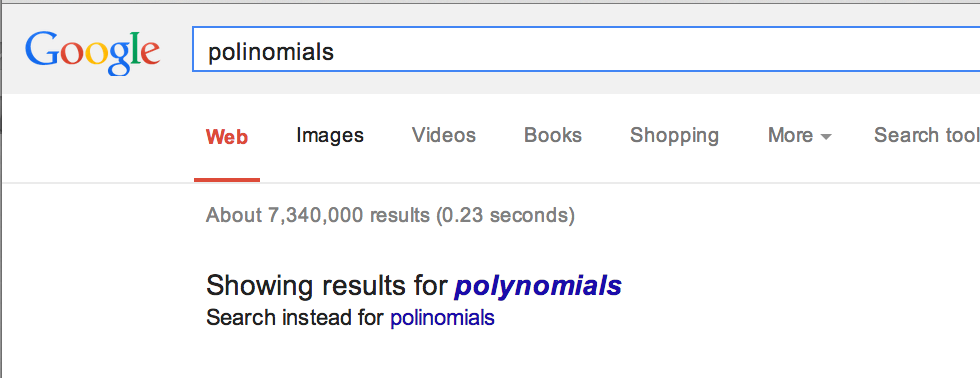
One year ago, searching for polinomials on Khan Academy's search page would give you no results. If you typed the same thing into Google you'd be efficiently and politely corrected.
I didn't have any illusions of making a solution as good as Google's, but I figured I could improve things for a significant number of users anyways 1.
The first thing I did was see if there was some library or tool that we could use to do some simple spellchecking. Khan Academy runs on Google App Engine's Python platform, so I needed a pure-Python library (installing CPython extensions is not allowed).
Whoosh was a good candidate, but it wasn't as memory efficient as I wanted 2. Integrating Whoosh with Google App Engine also looked error-prone. After looking around some more and not finding anything super useable, I decided to try something crazy.
I decided to build my own pure-Python spell checker.

I was expecting my mentor and others to balk at the idea (I was an intern during this time). But all I received were encouraging nods, so off I went.
To get things up and going quickly, I chose to follow a simple brute force algorithm like the one Peter Norvig describes in his awesome blog post. Soon I had something running that worked well and was super fast. There was a problem though.
Storing our English words in a Python dict consumed about 18 MB of space 3. Since my hope was that this code could run on all our frontend instances and work for all languages 4, our infrastructure team and I weren't super excited by this.

To reduce memory I first tried using Python's array module to build my own immutable hash table. This did indeed bring our memory usage down but made spellchecking take several seconds per query.
I found that the loss of speed came from doing way more things in Python code instead of CPython's super-fast dict implementation. This ruled out improving the performance through clever data structures. So I had to give up on my plans for an awesome succinct trie implementation and instead go hunting through the standard library to find the best native solution available.
Thus I arrived at the binary search implementation in the bisect module of Python's standard library.
The idea is simple. Store a hash of each word in a sorted array and then do binary search on that array. The hashes are small and can be tightly packed in less than 2 MB. Binary search is fast and allows the spell checking algorithm to service any query.
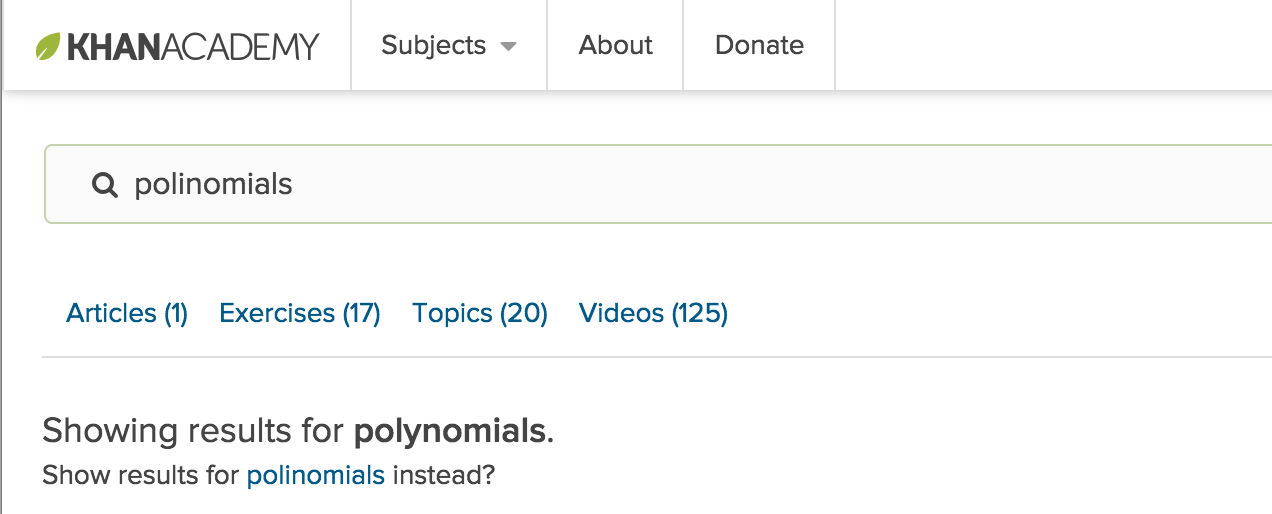
Best of all, it works.
Footnotes
-
I found that the 28% of the least frequent 16,000 queries and 18% of the most frequent 16,000 queries had typos within edit distance 2 of a known common word. I defined "common word" by creating a single dictionary from some freely licensed english dictionaries and all of Khan Academy's content. This was part of my preliminary research and was done to check that a autocorrecter was a useful feature. ↩
-
I came to this conclusion by auditing the code, which is (of course) not nearly as accurate as actually running benchmarks. If you're familiar with Whoosh and think I came to the wrong conclusion, please let me know. ↩
-
Once I got something working at all, I invested time into making a script that would give me metrics on our speed, memory usage, and accuracy. Pympler was used to get the size of the dictionary implementations as well as the max memory usage when running the algorithm. ↩
-
18 MB is a lot of space for our frontend instances, but we could've spared it. I never ended up adding support for other languages, so I think it would have been reasonable to just ship with the native
dict. The time to optimize should have been when I was adding support for other languages. ↩